梶研 [LSTMで行動認識をする]
2024年2月27日
LSTMで行動認識をする
出席率
- 3年セミナー:??%
スケジュール
短期的な予定
- mocopi と お料理センシング
- シーンとランドマークを決める(~2月上旬)
- SVM で動作判別する
- 機械学習を深める
- 機械学習の手法を知る
- 使う手法を決める
- データセットを探す
- 機械学習(LSTM)する
- 精度を上げる
- ?
- お料理センシング
- お料理でどんな動作があるかを知る
- ?
- 論文書く
- 発表
- BLEビーコンのuuidを書き換えたい
- 通信内容を読み解く
- 実装してみる
長期的な予定
- ~?月 シーン検知?をする
- ~?月 論文を書く
- ~?月 論文発表したい
進捗報告
データセットを探す
国際会議CVPR2021にて住空間行動認識コンペティションを開催します
http://ec2-52-25-205-214.us-west-2.compute.amazonaws.com/files/activity_net.v1-3.min.json
私のブックマーク「センサを用いた行動認識」bookmark_vol36-no2/
Moreaux, M., Ortiz, M. G., Ferran´e, I. and Lerasle, F.: Benchmark for kitchen20, a daily life dataset for audiobased human action recognition, Int. Conf. ContentBased Multimedia Indexing (CBMI), IEEE, pp. 1–6 (2019).
とても良さそうだったが論文が見れなかった...
→ モデル作成に用いる kitchen20 データセット [11] の各音源の長さは 5 秒である 音声だったかも
探すの飽きたので一旦適当なデータセットで試す
好きな物を題材にするのはやる気が出て良いと思います
時系列データではないため LSTM では使えなかった
https://allisonhorst.github.io/palmerpenguins/
行動認識してる研究があった
加速度データからの機械学習による行動認識
福井大学 大学院工学研究科 研究報告 第68巻2020年3月
https://www.eng.u-fukui.ac.jp/wp-content/uploads/vol68_59-66.pdf
4.1 用いるデータセット
この節では、使用するデータセットの説明をする。
データセットは、スマートフォンによって収集された3 軸加速度センサを用いたデータである HASC コーパスを用る。このデータセットの対象としている行動は、停止 (stay )、歩行 ( walk )、ジョギング ( jog )、スキップ (skip )、階段を上がる ( stUp )、階段を下る ( stDown )の 6 種類であり、それぞれの 3 軸加速度信号データ (csv )、メタデータ ( meta )、ラベルデータ ( label ) の3 種類のデータ形式が記録されている。また、データセットは、大きく分けてセグメントデータとシーケンスデータに分けることができる。
梶先生らの HASC コーパス を使っていた
LSTM をしてみる
流れを確認する
簡単なLSTMをしている記事があった
https://qiita.com/sloth-hobby/items/93982c79a70b452b2e0a
流れ
- (三角関数のパラメーラを設定)
- データセットを生成
- 値 と ラベル (と 時間)
- データセットを学習用とテスト用に分ける
- sklearn.model_selection.train_test_split を使っている
- 値 と ラベル をシャッフルする
- sklearn.utils.shuffle
- Tensor型 にする
- torch.Tensor
- 損失を計算する?
- 損失に関する各パラメータの勾配を計算する?
- 予測する
より詳しい説明
https://hilinker.hatenablog.com/entry/2018/06/23/204910
解きたいタスクによって大きく変わるらしい
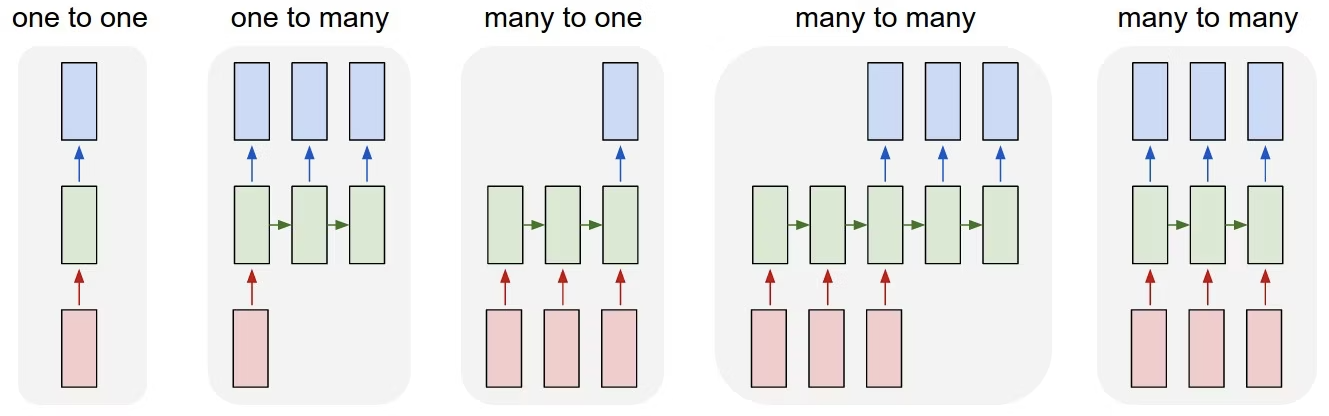
三角関数の連続する3点から続きの1点を出す → many to one
分類問題は many to one
参考: https://qiita.com/m__k/items/841950a57a0d7ff05506
書く
データセットを扱いやすい形にする
BasicActivity/{index}_{label}/{PersonID}/HASC*-acc.csv - time x y z
複数のファイルに分かれているためひとつのファイルにまとめる
BasicActivity/{PersonID}/{PersonID}-acc.csv - time x y z label
面倒だったので 加速度だけでやる
ソースコード
1 def __init__(self, person_id: str, path: str) -> None: 2 labels = ['stay', 'walk', 'jog', 'skip', 'stUp', 'stDown'] 3 4 files = [ 5 { 6 "label": l, 7 "acc": str(list( 8 pathlib 9 .Path(f"{path}/{i+1}_{l}/{person_id}") 10 .glob("*-acc.csv") 11 )[0]), 12 "gyro": str(list( 13 pathlib 14 .Path(f"{path}/{i+1}_{l}/{person_id}") 15 .glob("*-gyro.csv") 16 )[0]), 17 "pressure": str(list( 18 pathlib 19 .Path(f"{path}/{i+1}_{l}/{person_id}") 20 .glob("*-pressure.csv") 21 )[0]), 22 } 23 for i, l in enumerate(labels) 24 ] 25 26 df_acc = pd.concat([ 27 pd.read_csv(f["acc"], header=None, names=["time", "x", "y", "z"]) 28 .assign(label=f["label"]) 29 for f in files 30 ]) 31 df_gyro = pd.concat([ 32 pd.read_csv(f["gyro"], header=None, names=["time", "pressure"]) 33 .assign(label=f["label"]) 34 for f in files 35 ]) 36 df_pressure = pd.concat([ 37 pd.read_csv(f["pressure"], header=None, names=["time", "x", "y", "z"]) 38 .assign(label=f["label"]) 39 for f in files 40 ]) 41 42 self.df_acc = df_acc 43 self.df_gyro = df_gyro 44 self.df_pressure = df_pressure 45 46 def make_dataset(self, sequence_length: int): 47 dataset_inputs = [] 48 dataset_labels = [] 49 dataset_times = [] 50 51 # self.df_acc を時系列データに変換 52 for i, row in enumerate(self.df_acc.itertuples()): 53 # dataframe の長さを超える場合は終了 54 if i+sequence_length > len(self.df_acc): 55 break 56 # ラベルが変わる場合はスキップ 57 if i > 0 and self.df_acc.iloc[i-1].label != row.label: 58 continue 59 dataset_inputs.append(r for r in self.df_acc[i:i+sequence_length]) 60 dataset_labels.append(row.label) 61 dataset_times.append(row.time) 62 63 return dataset_inputs, dataset_labels, dataset_times
訓練用とテスト用に分割する
1inputs, labels, _ = train.make_dataset(sequence_length) 2train_inputs, test_inputs, train_labels, test_labels = train_test_split(inputs, labels, test_size=test_size, shuffle=False)
評価関数を宣言
評価関数とは
評価関数とは学習させたモデルの良さを測る指標を指します。
1criterion = nn.CrossEntropyLoss()
二乗平均誤差(RMSE) みたいな役割ぽい
参考: https://qiita.com/monda00/items/a2ee8e0da51953c24da8
最適化関数を宣言
最適化関数とは
損失関数を用いて正解値と予測値の差を微分することで、勾配を求めることができます。
この勾配を利用してどのくらいの強度でパラメータを更新するかを決めているのが最適化関数です。
とにかくパラメータの方向性をいい感じにしてくれるらしい
参考: https://qiita.com/Lapinna/items/d5c331b74c99767ca04a
なんやかんやする
ephoc数: 訓練データを何回繰り返して学習させるかの回数
batch数: データセットを分割する. 1度に処理を行う数
1for ephoch in ephoc数: 2 for batch in batch数: 3 学習の処理
ソースコード
1 def train( 2 self, 3 train_inputs: list, 4 train_labels: list, 5 test_inputs: list, 6 test_labels: list, 7 epoch_num: int, 8 batch_size: int, 9 sequence_length: int, 10 ): 11 train_batch_num = len(train_inputs) // batch_size 12 test_batch_num = len(test_inputs) // batch_size 13 14 for epoch in range(epoch_num): 15 print("-" * 20) 16 print(f"Epoch {epoch+1}/{epoch_num}") 17 train_loss = 0.0 18 test_loss = 0.0 19 shuffled_train_inputs, shuffled_train_labels = shuffle( 20 train_inputs, train_labels 21 ) 22 23 np.savetxt( 24 "shuffled_train_inputs.csv", 25 np.array(shuffled_train_inputs).reshape( 26 -1, np.array(shuffled_train_inputs).shape[-1] 27 ), 28 delimiter=",", 29 ) 30 31 for batch in range(train_batch_num): 32 start = batch * batch_size 33 end = start + batch_size 34 35 np_train_inputs = np.array(shuffled_train_inputs[start:end]).astype( 36 np.float64 37 ) 38 np_train_labels = np.array(shuffled_train_labels[start:end]).astype( 39 np.int64 40 ) 41 loss, _ = self.train_step(np_train_inputs, np_train_labels) 42 train_loss += loss.item() 43 44 for batch in range(test_batch_num): 45 start = batch * batch_size 46 end = start + batch_size 47 48 loss, _ = self.train_step( 49 np.array(test_inputs[start:end]).astype(np.float64), 50 np.array(test_labels[start:end]).astype(np.int64), 51 ) 52 test_loss += loss.item() 53 54 print(f"loss: {train_loss / train_batch_num}") 55 print(f'test_loss: {test_loss / test_batch_num}') 56 57 def train_step(self, inputs, labels): 58 inputs_tensor = torch.tensor(inputs, dtype=torch.float32).to(self.device) 59 labels_tensor = torch.tensor(labels).to(self.device) 60 61 self.model.eval() 62 preds = self.model(inputs_tensor) 63 loss = self.criterion(preds, labels_tensor) 64 65 return loss, preds
実行結果
device: cpu
--------------------
Epoch 1/100
loss: 1.80343093945269
test_loss: 1.7852103145498979
--------------------
Epoch 2/100
loss: 1.8034178761013768
test_loss: 1.7852103145498979
--------------------
Epoch 3/100
loss: 1.8034281317602123
test_loss: 1.7852103145498979
--------------------
Epoch 4/100
loss: 1.8034172628009528
test_loss: 1.7852103145498979
--------------------
Epoch 5/100
loss: 1.8034309844175975
test_loss: 1.7852103145498979
--------------------
Epoch 6/100
loss: 1.8034331908351497
test_loss: 1.7852103145498979
...
loss: 1.803422716103102
test_loss: 1.7852103145498979
--------------------
Epoch 12/100
loss が減らない.
ChatGPT に聞いてみた
訓練がうまくいかない理由の一つは、学習率 (lr) の値が適切でない可能性があります。学習率はモデルの訓練中に重要な役割を果たし、適切な値を見つけることが重要です。学習率が高すぎると、訓練が収束せずに振動する可能性があります。逆に、学習率が低すぎると、訓練が収束するまでに非常に長い時間がかかる可能性があります。
なるほど
0.0001 から 1 にしてみた
device: cpu
--------------------
Epoch 1/100
loss: 1.7967431503429747
test_loss: 1.7872365692205596
--------------------
Epoch 2/100
loss: 1.796769555723458
test_loss: 1.7872365692205596
--------------------
Epoch 3/100
loss: 1.796803759901147
test_loss: 1.7872365692205596
--------------------
Epoch 4/100
loss: 1.7967799776478817
test_loss: 1.7872365692205596
--------------------
Epoch 5/100
loss: 1.7967207206968676
test_loss: 1.7872365692205596
--------------------
Epoch 6/100
loss: 1.79678154043984
test_loss: 1.7872365692205596
...
--------------------
Epoch 100/100
loss: 1.7967986835722338
test_loss: 1.7872365692205596
変わらない. 0.01 100 なども試したが大差なかった
原因候補
- 最適化関数が良くない?
- sin波の予測 と 分類 ではやり方が違うのかもしれない
- 適当に label 渡したのが良くない
最適化関数を変えてみる
optim.Adam から optim.SGD にした
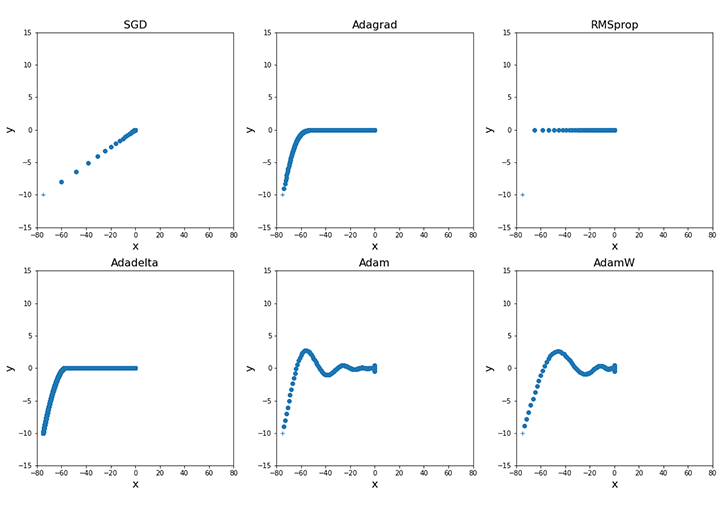
参考: Pytorchの様々な最適化手法
1device: cpu 2-------------------- 3Epoch 1/100 4loss: 1.809930482977315 5test_loss: 1.721430358133818 6-------------------- 7Epoch 2/100 8loss: 1.8099145392576854 9test_loss: 1.721430358133818 10-------------------- 11Epoch 3/100 12loss: 1.8099606868467832 13test_loss: 1.721430358133818 14-------------------- 15Epoch 4/100 16loss: 1.8100076438042156 17test_loss: 1.721430358133818 18-------------------- 19Epoch 5/100 20loss: 1.8099237277842404 21test_loss: 1.721430358133818 22-------------------- 23Epoch 6/100 24loss: 1.8099288961343598 25test_loss: 1.721430358133818 26... 27-------------------- 28Epoch 100/100 29loss: 1.8099035244239003 30test_loss: 1.721430358133818
変わらなかった. そもそも最適化関数が使えてる?
→ optimizer.step() を入れてなかった
結果
device: cpu
--------------------
Epoch 1/100
loss: 1.4727532474095362
test_loss: 2.458821142043775
--------------------
Epoch 2/100
loss: 3.9363968978848374
test_loss: 47.90312148220191
--------------------
Epoch 3/100
loss: 22.853781702225668
test_loss: 350.9249111309386
--------------------
Epoch 4/100
loss: 43.75640468430101
test_loss: 69.1852414315207
--------------------
Epoch 5/100
loss: 172.5352889696757
test_loss: 838.7717777720669
--------------------
Epoch 6/100
loss: 140.68897648024978
test_loss: 245.76162933885004
...
loss: 222.82399281284265
test_loss: 668.8828098230194
--------------------
Epoch 10/100
変化したが爆上がりした
0.0001 にしてみた
1device: cpu 2-------------------- 3Epoch 1/1000 4loss: 1.7136963245115782 5test_loss: 2.322023772356803 6-------------------- 7Epoch 2/1000 8loss: 1.564926897224627 9test_loss: 2.430806122328106 10-------------------- 11Epoch 3/1000 12loss: 1.6254029938003474 13test_loss: 1.955993468301338 14-------------------- 15... 16loss: 0.7991769483737778 17test_loss: 3.40365913876316 18-------------------- 19Epoch 104/1000
1device: cpu 2-------------------- 3Epoch 1/1000 4loss: 1.630137525629579 5test_loss: 2.442890736094692 6-------------------- 7Epoch 2/1000 8loss: 1.7019225055711311 9test_loss: 1.8877409361956412 10-------------------- 11Epoch 3/1000 12loss: 1.540266997458642 13test_loss: 1.795748932319775 14-------------------- 15... 16loss: 0.31551139612208334 17test_loss: 0.7359745272092129 18-------------------- 19Epoch 101/1000 20... 21loss: 1.1991943183698153 22test_loss: 1.0757994573612355 23-------------------- 24Epoch 167/1000
良い感じになってきた.
Epoch数 を上げすぎると過学習になった
パラメータを変えて精度を上げる必要がありそう
(主成分分析は)
これをどう使えばいいかは分からない
ある程度分かってくると機械学習も面白い
メモ
私のブックマーク「センサを用いた行動認識」
https://www.ai-gakkai.or.jp/resource/my-bookmark/my-bookmark_vol36-no2/
進路関係
なし
余談
関ヶ原に行ってきた
道中の犬山城

道中の大垣城

関ヶ原

道中の墨俣一夜城
